Why It Matters
Your Pain Points
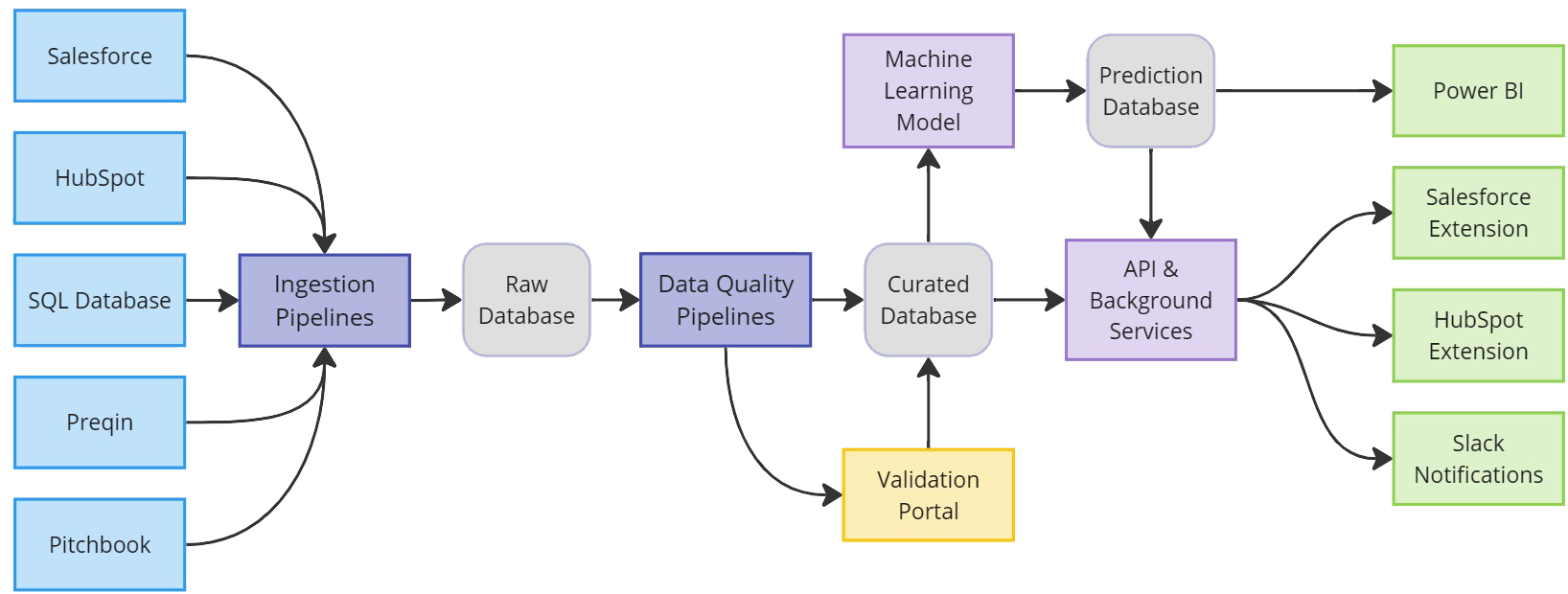
Fragmented ETL processes, unchecked format inconsistencies, and hidden duplicates lead to unreliable data, slowed analytics, and costly manual fixes. Organizations also struggle with hidden data errors, model drift, and bias that undermine trust in AI-driven decisions. Without systematic reviews, these issues often go undetected until they impact critical business workflows.


Solution Impact
A unified data quality layer that monitors every ingestion step, auto-detects and resolves errors (from formatting to relationships), and empowers your team with tools and training for sustainable data hygiene. Plus a recurring, end-to-end evaluation process that uncovers data inconsistencies and model weaknesses, delivers concrete remediation plans, and continuously refines your AI capabilities—ensuring high data integrity and peak model performance.