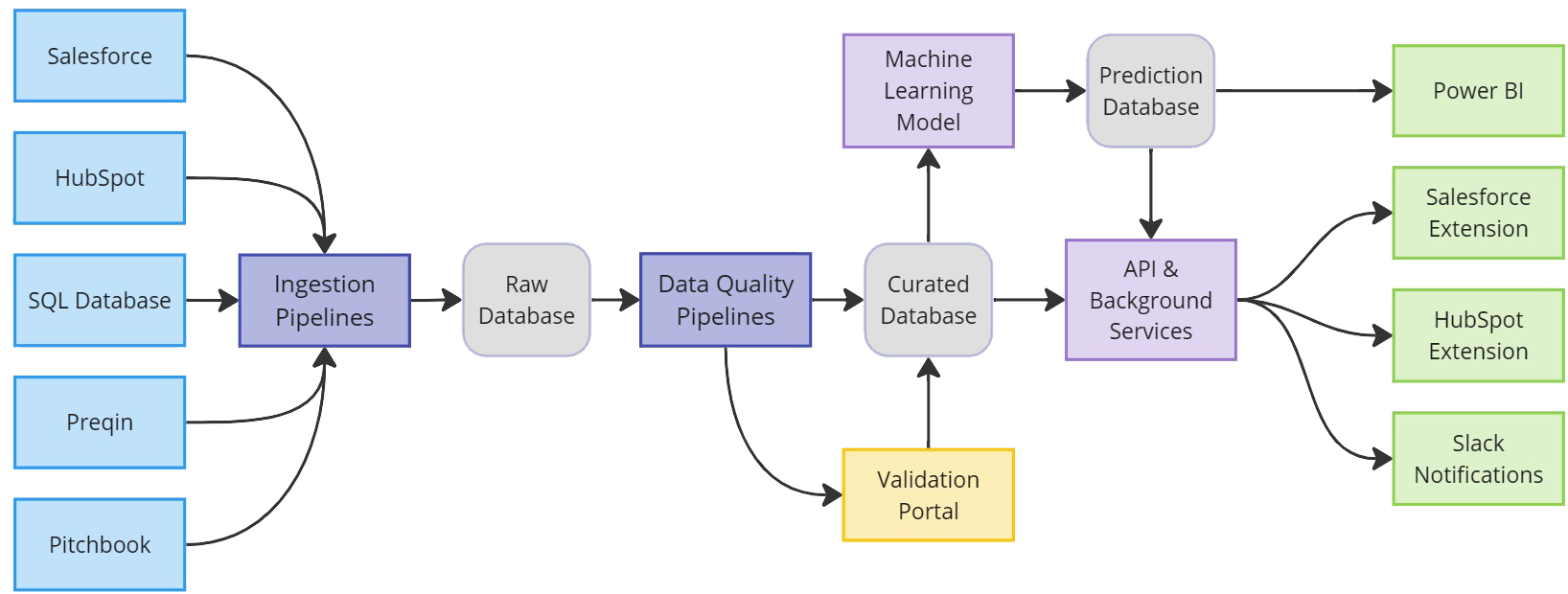
 Figure: Simplified image of the solution architecture
Figure: Simplified image of the solution architecture
1. Introduction & Goal
A leading private equity firm struggled with fragmented, duplicate data across multiple systems and an unreliable third-party tool.
- Unified Data Platform: Custom Azure Databricks pipeline into Delta Lake with rigorous cleansing and deduplication.
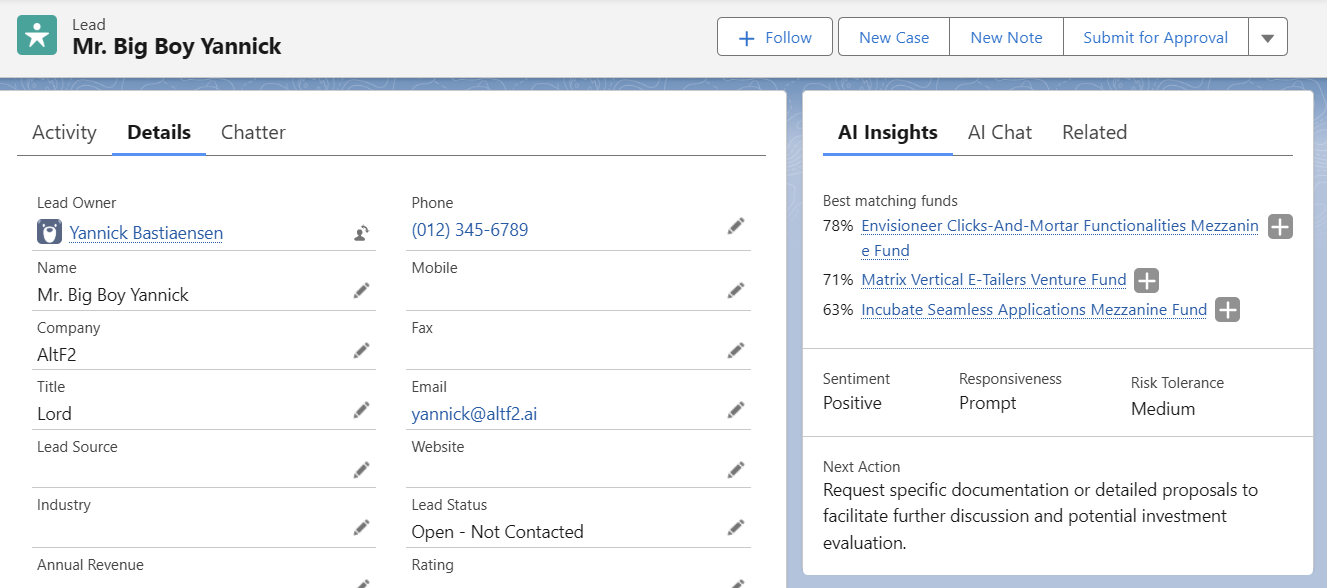
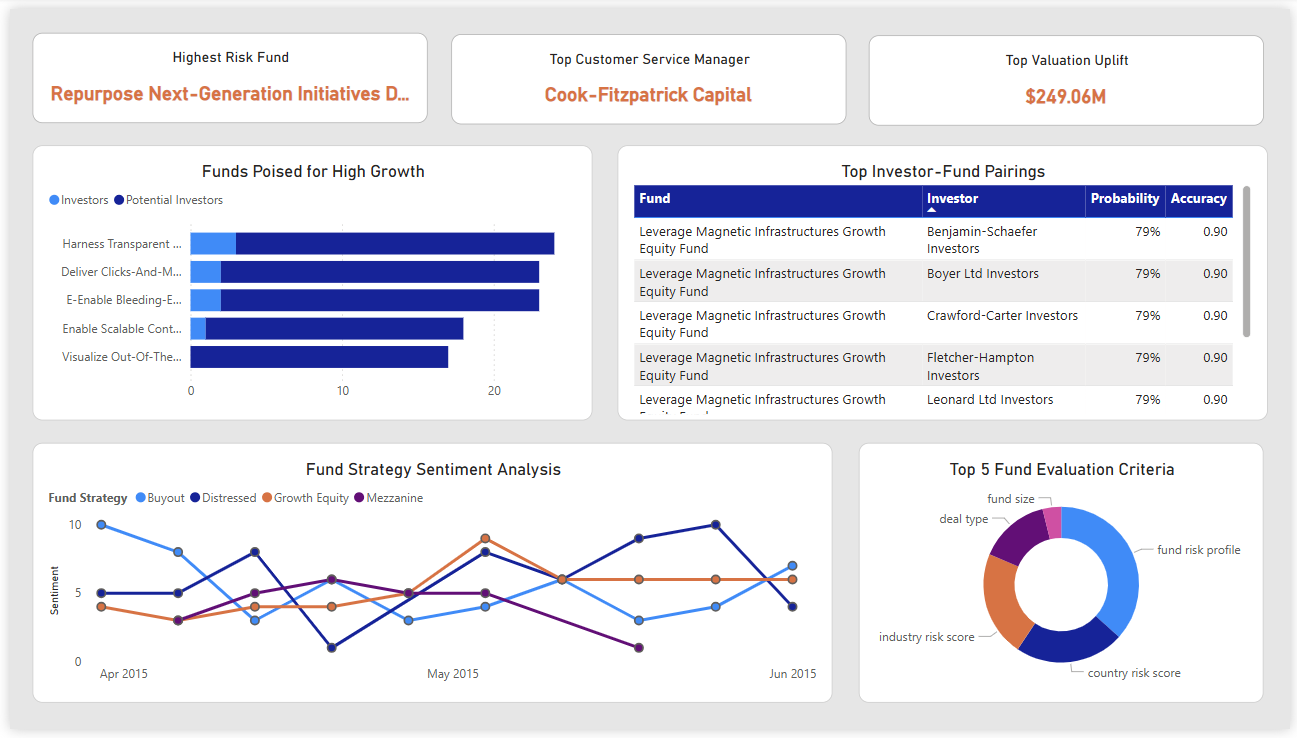
- AI-Powered Insights: Expose clean data via Azure Synapse to drive cross-sell recommendations, risk scoring, and sentiment analysis.
- Automated Workflows: Embed real-time AI APIs and alerts in Salesforce & HubSpot for predictive next-best-actions.
The result: proactive, AI-driven sales optimization that boosts deal velocity and revenue.
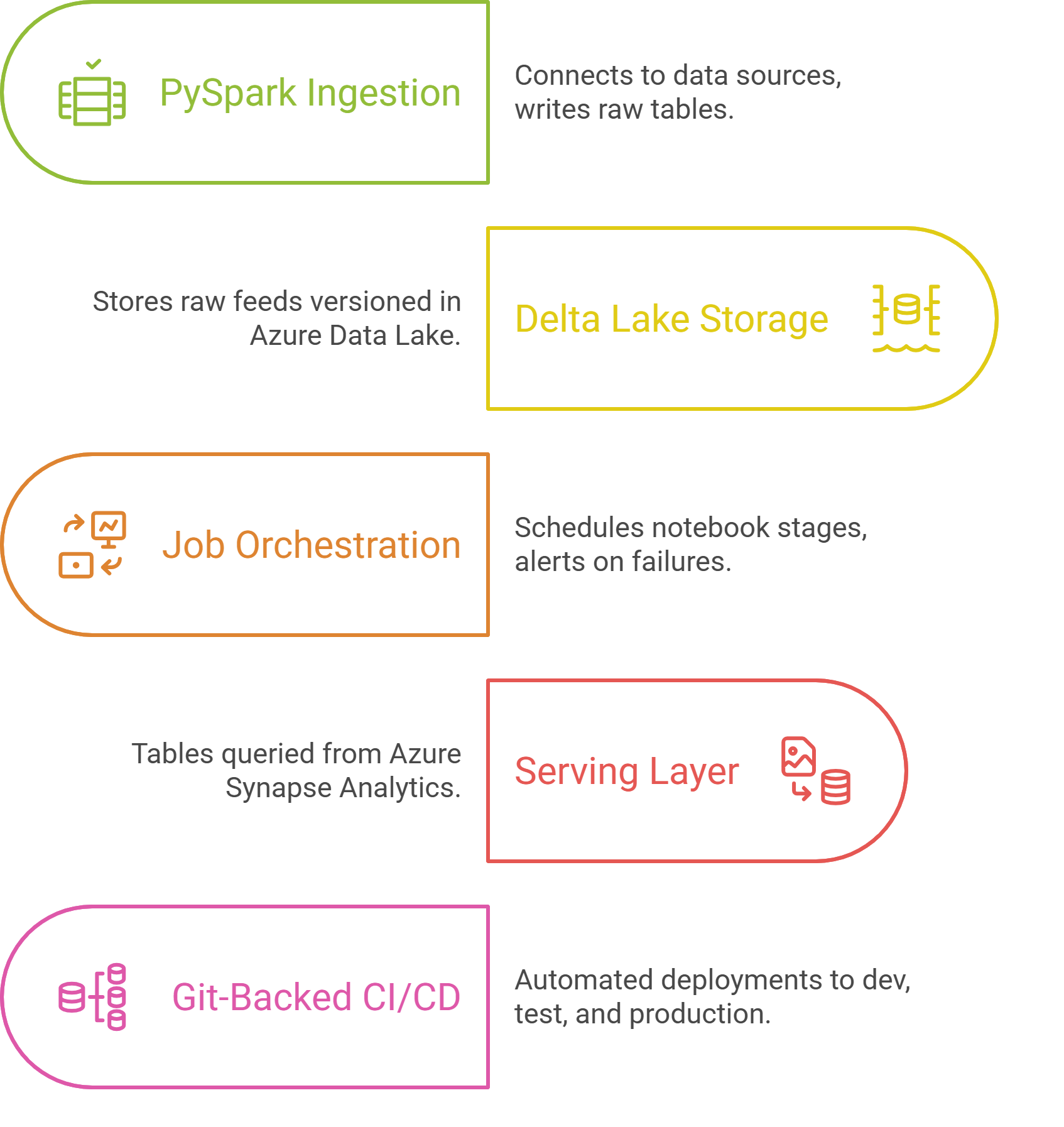
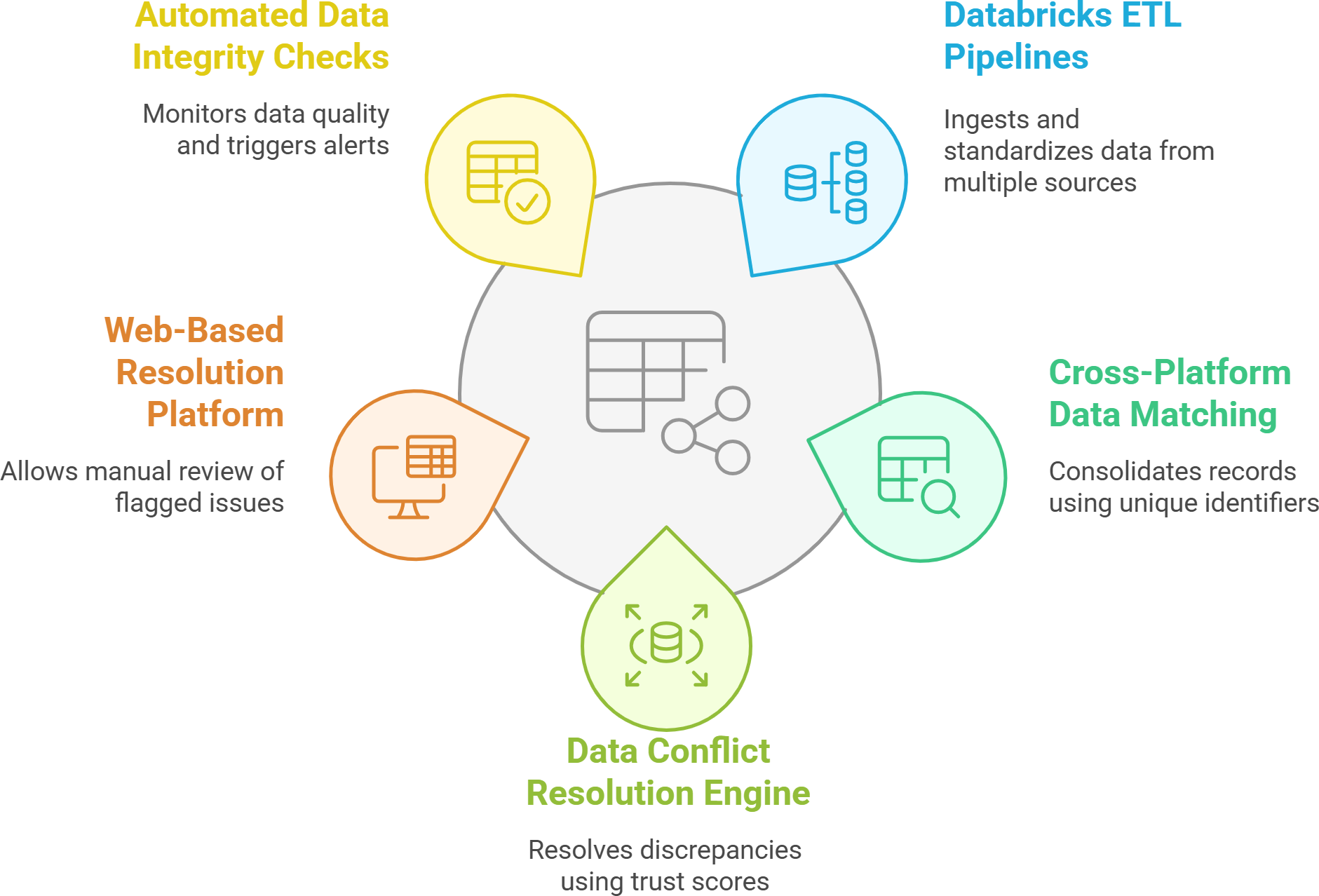
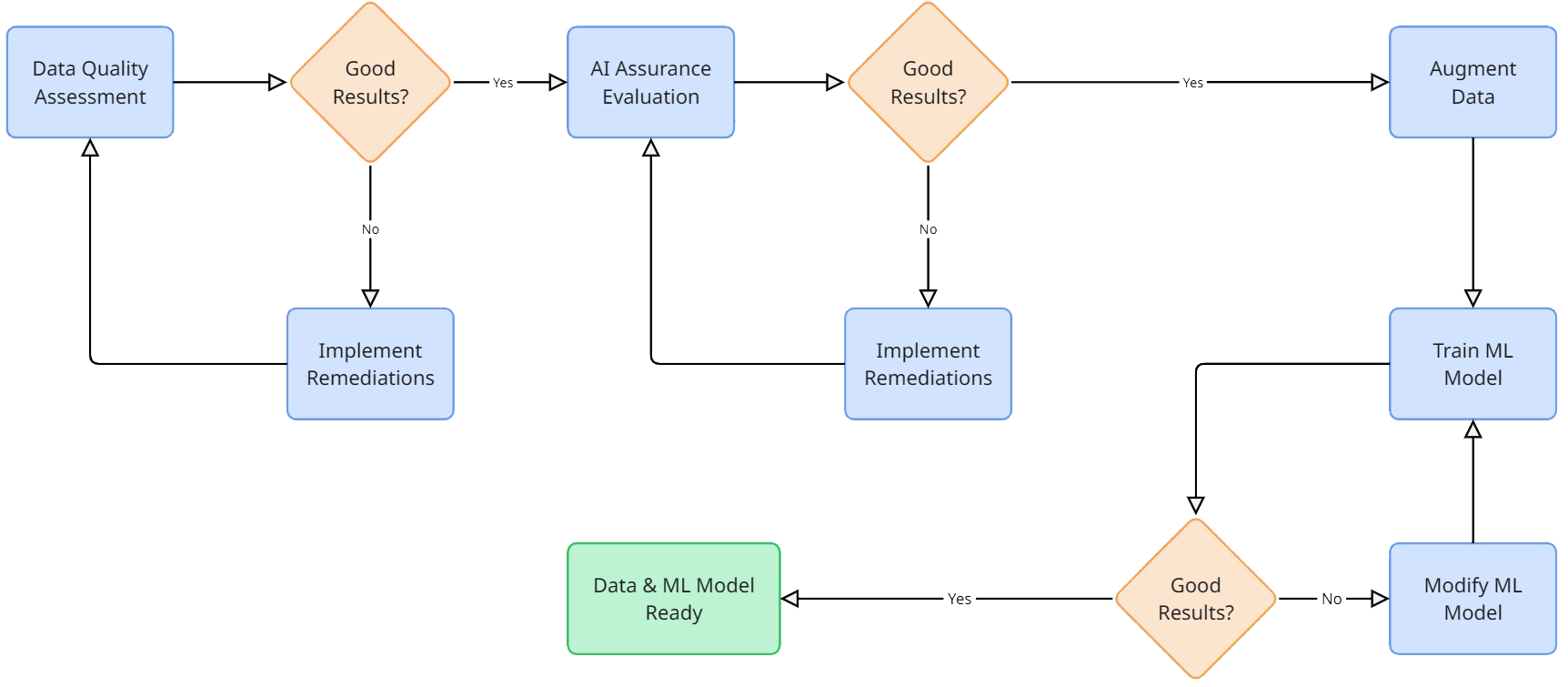 Figure: Iterative training process for a custom machine learning model
Figure: Iterative training process for a custom machine learning model